TableBuilder持久化MemTable数据
简介
LevelDB 进行 key-value 写过程中,首先会将 key-value 数据存放在内存表 MemTable 结构当中,当 MemTable 超过设定域值��时,使用 TableBuilder 将内存数据刷写到磁盘文件中。
如下图所示,逐步介绍 key-value 数据是如何从 MemTable 结构存储到磁盘文件。
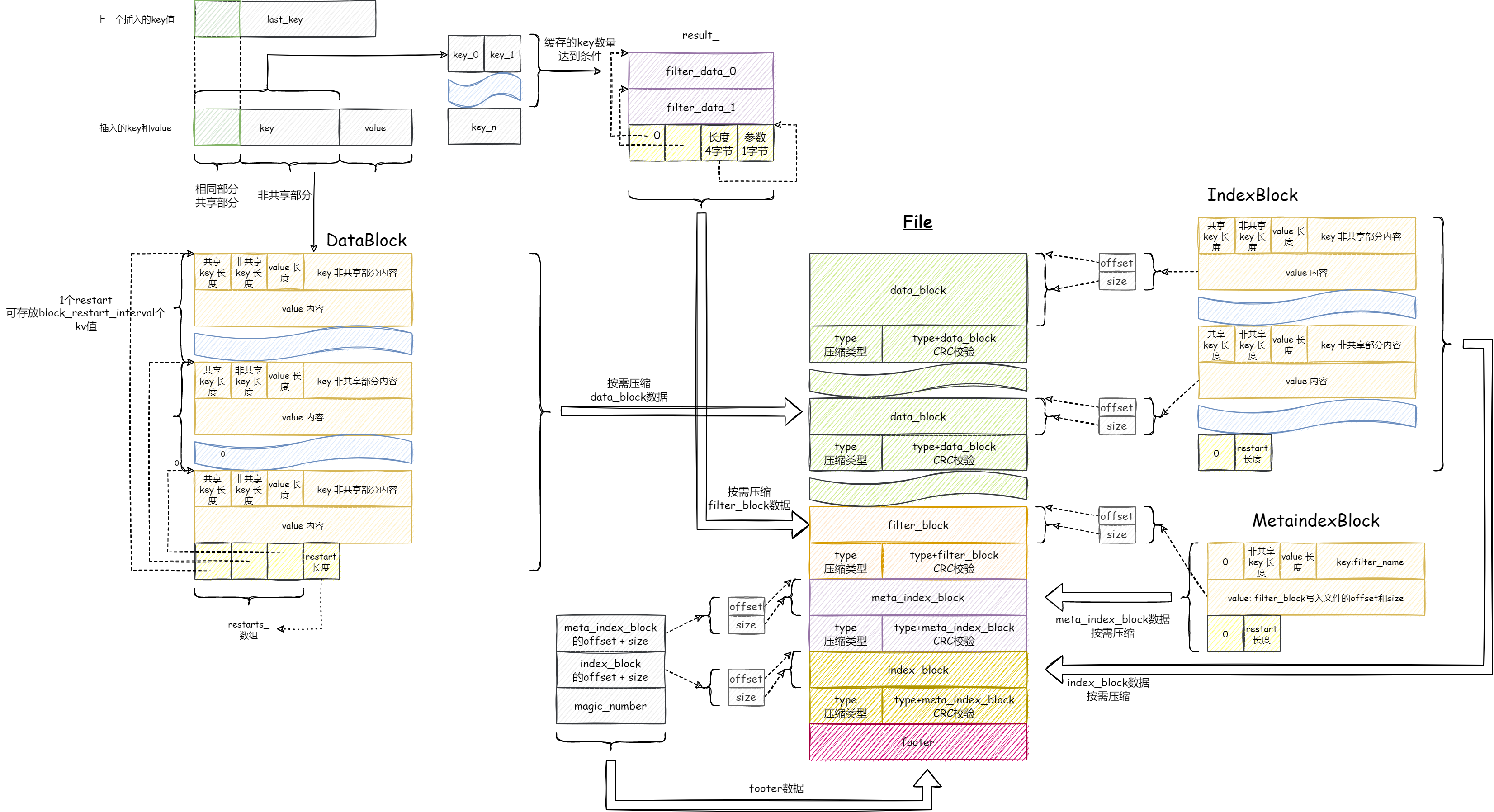
从 MemTable 到 TableBuilder
MemTable 提供迭代器接口以顺序访问 key-value 数据,并且保证 key 数据唯一, TableBuilder 便以该次序接收 key-value 数据,转化为磁盘格式进行写入。
key 数据压缩
对于 key-value 型存储,上层写入数据的 key 一般来说都具有某种特征,例如连续增长的 id 字符串,从 00000000 到 99999999 , TableBuilder 接收这样特征的有序字符串,便可提取其公共前缀进行压缩。
例如接收到的第一个 key 为 00000000 ,第二个 key 为 00000001 ,那么存放时可以仅存放一次 7 字节的相同前缀,省略前缀后还需要引入两个新的字段才能还原整个 key:共同前缀长度和非共同前缀长度。
大体处理思路如下,假设有磁盘数据 0800000000712 :
- 顺序读取两字节,即共同前缀长度
0字节和非共同前缀长度8字节。 - 顺序读取八字节,由于共同前缀长度为
0字节,直接组成key数据为00000000。 - 顺序读取两字节,即共同前缀长度
7字节和非共同前缀长度1字节。 - 顺序读取一字节,与前一个数据的前
7字节共同构造新的key数据为00000001。
重启点
若每个 key 都采取前缀压缩,还原某个 key 时必然需要从文件头读取数据,进行 key 恢复,复杂度太高,不利于检索。
LevelDB 采取重启点方式解决该问题:默认每 16 个 key 进行重启,重启时的第一个 key 不进行压缩,之后的 15 个 key 采取上述压缩方式。
为了能够快速索引 key 的位置,记录所有重启点位置,查找时对重启点进行二分查找(重启时的第一个 key 是完整的,可以参与比较),锁定目标值所在重启点区间,从重启点开始顺序访问还原出 key 数据与目标值进行比较。
数据分块
如果文件中仅存放 key-value 数据和用于索引 key 的重启点数据,那么检索策略有如下几种:
-
将整个文件读入内存,进行检索,由于文件大小远大于内存大小,方案不可行。
-
将整个重启点数据读入内存,再根据重启点位置,读取每个重启点对应的完整
key数据到内存,在内存中进行二分查找,锁定目标值可能位于哪两个重启点之间,从重启点开始读取数据,恢复出压缩的key与目标值进行比较。
方案二看起来很好,但是忽略了一个问题,在读取每个重启点的第一个完整 key 时,虽然可能仅需读取几字节数据,但是操作系统一次 IO 可能会读取 4kB 数据到缓存中,极大地浪费了盘 IO 带宽。
所以,如果每次读取的数据大小和操作系统真实读取到缓存的数据大小一致,能够有效利用 IO 带宽。
LevelDB 采取数据分块方式进行写入:如果写入的 key-value 数据和重启点数据超过设定阈值,就形成一个数据分块并写入文件中。要访问某个数据分块,还需要索引数据来记录每个数据分块的偏移量和大小。
索引数据以 key-value 方式存放到索引分块中(一个文件存在多个数据分块但只有一个索引分块)。接下来讨论索引数据的 key 值和 value 值选取:
索引数据中 value 值自然为存放数据分块的偏移位置和大小。而索引数据中 key 值 LevelDB 采取如下方式,其语义为当前数据分块中“最大”的 key :
当前数据分块最后一个 key 为 k1 ,下一个数据分块第一个 key 为 k2 ,取 k1 和 k2 共同前缀为 k ,第一个不一样的字符 +1 为 d ,组合为 kd ,若 kd != k2 则索引数据 key 值为 kd 否则为 k1 。例如 k1 = 1234567, k2 = 345678 则索引数据存放的 key 值为 2 ,满足上述语��义(索引数据 key 值为当前数据分块中“最大”的 key ,其大小没有落入下一个数据分区)。上述做法有效地压缩了存放数据。
数据分块再存放过程中还支持使用压缩算法对数据进行进一步压缩,所以最终需要在每个数据分块尾部写入两个字段:是否压缩以及校验码。
布隆过滤器
LevelDB 支持使用过滤器,快速判断某个数据分块是否含有目标 key 值,从而避免读取整个数据分块,转而使用占用内存空间较少的过滤器数据。默认布隆过滤器基本思路如下图所示:
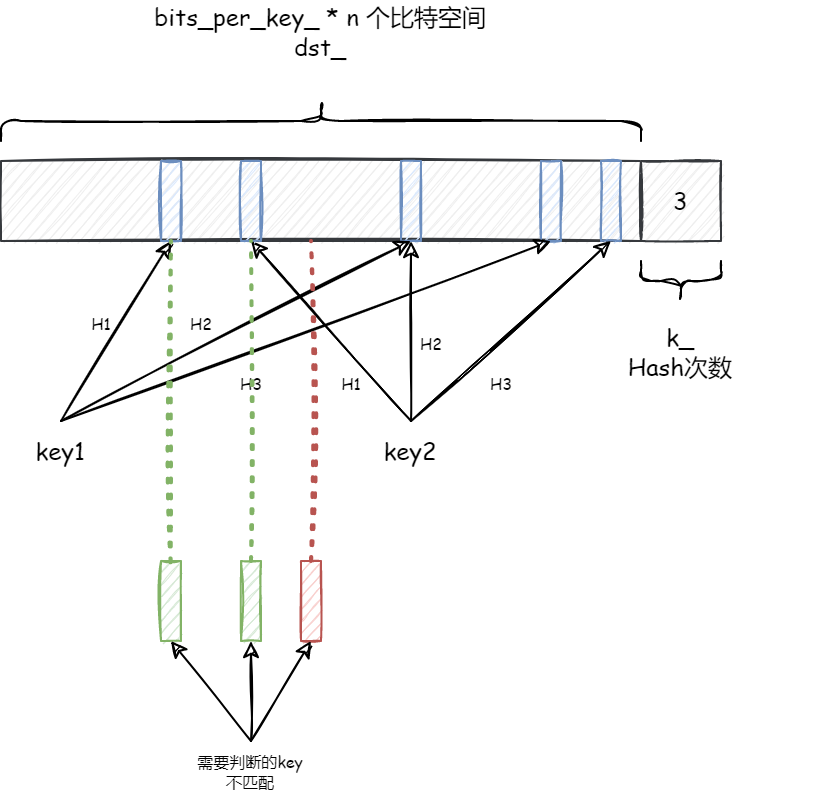
当写入数据分块时,过滤器记录当前数据区块的所有 key 值,对每一个 key 值进行 k 次哈希,填充到对应的过滤器数据区域中。对每个数据分区都生成一个这样的过滤器数据区域,最后需加入索引数组来记录过滤器数据对应的偏移量。
LevelDB 中采用一种更简单的方式来记录偏移量:利用 数据分块的偏移 / 2KB 来生成索引下标,索引中记录对应的过滤器数据的起始位。
例如当前生成的过滤器数据为 filterdata0 | filterdata1 ,数据分块偏移分别为 0KB 和 5KB ,则生成的索引数组如下:
filterindex[0] = filterdata0.offset
filterindex[1] = filterdata0.offset
filterindex[2] = filterdata1.offset
当访问第二个数据分块时,使用 5KB / 2Kb = 2 即访问 filterindex[2] 对应的过滤器数据。
注意:数据分块如果小于 2KB 对于当前数据分块不会产生过滤器数据,仅当数据分块大小之和大于 2KB 才进行过滤器数据生成。
实现
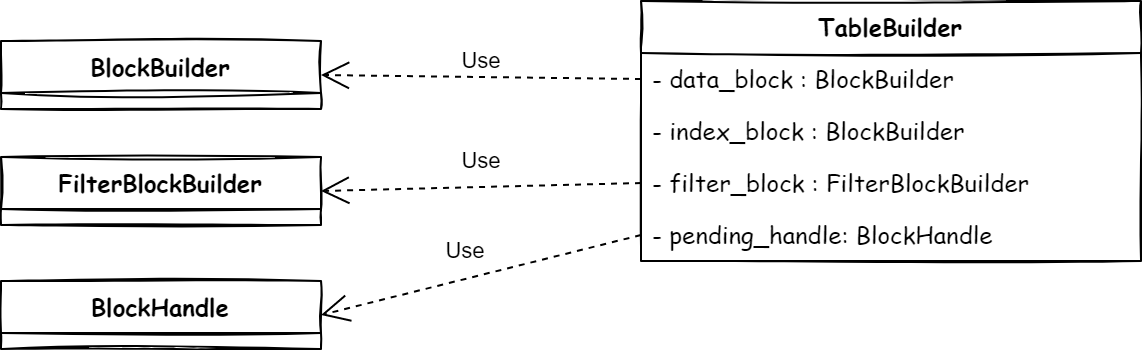
依赖关系如图:TableBuilder 负责接收 Key-Value 数据,将数据传递给 BlockBuilder 和 FilterBlockBuilder 并在合适的时机使其进行刷盘操作,刷盘操作的偏移位置由 BlockHandle 记录。
BlockBuilder
class BlockBuilder {
private:
const Options *options_; // 配置项
std::string buffer_; // 缓存
std::vector<uint32_t> restarts_; // 重启点
int counter_; // 记录写入多少 key 数据
bool finished_; // 标记是否 Finish
std::string last_key_; // 上一个写入的 key
};
// 第一个重启点为 0
BlockBuilder::BlockBuilder(const Options *options)
: options_(options), restarts_(), counter_(0), finished_(false) {
assert(options->block_restart_interval >= 1);
restarts_.push_back(0);
}
// 估算写入一个数据分块占用多大磁盘空间
// 写入 key-value 数据大小 + 重启点数组大小 + 重启点长度记录值大小
size_t BlockBuilder::CurrentSizeEstimate() const {
return (buffer_.size() +
restarts_.size() * sizeof(uint32_t) +
sizeof(uint32_t));
}
// 将当前 BlockBuilder 中数据形成下盘格式
// buffer_中已经是 key-value 数据了,只需要将重启点数组和长度写入即可
Slice BlockBuilder::Finish() {
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
// 写入数据后,调用该接口清空,开启新的数据分块
// 避免重新 new 一个新的 BlockBuilder 以次节省内存
void BlockBuilder::Reset() {
buffer_.clear();
restarts_.clear();
restarts_.push_back(0);
counter_ = 0;
finished_ = false;
last_key_.clear();
}
// 数据写入
void BlockBuilder::Add(const Slice &key, const Slice &value) {
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty()
|| options_->comparator->Compare(key, last_key_piece) > 0);
// 共同前缀长度,默认为 0
size_t shared = 0;
// 还不需要重启,即前缀可压缩,查找共同前缀长度
if (counter_ < options_->block_restart_interval) {
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// �需要重启,记录下重启点
restarts_.push_back(buffer_.size());
counter_ = 0;
}
// 非共同长度
const size_t non_shared = key.size() - shared;
// 写入数据共同前缀长度/非共同前缀长度/value的大小
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// 写入key非共同前缀部分/写入value数据
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// 更新下最后一个key
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
FilterBlockBuilder
class FilterBlockBuilder {
private:
void GenerateFilter();
const FilterPolicy *policy_; // 自定义过滤器函数
std::string keys_; // 将所有key都以append形式写入keys_字符串
std::vector<size_t> start_; // 记录keys_字符串中每个key的长度
std::string result_; // 过滤器结果
std::vector<Slice> tmp_keys_; // 传递给 policy_ 的所有 key 值
std::vector<uint32_t> filter_offsets_; // 过滤器结果偏移
};
// 每 2kb 一个索引点,见 StartBlock 函数
static const size_t kFilterBaseLg = 11;
static const size_t kFilterBase = 1 << kFilterBaseLg;
// 缓存每个 key 数据到 keys_ 中
// 每个 key 长度到 start_
void FilterBlockBuilder::AddKey(const Slice &key) {
Slice k = key;
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}
// 开始一块新的数据分块时,需要生成上一块的过滤器数据
// 例如 [0~7KB) 为一个数据分块
// 当处理下一个数据分块,即 7KB 偏移的数据分块时,生成 3 个索引点
// index[2] = index[1] = index[0]
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
// 生成过滤器数据
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size();
// 当 key 数量为 0 时,存放的偏移和上一个应该是相同的
if (num_keys == 0) {
filter_offsets_.push_back(result_.size());
return;
}
// start 数组存放所有 key append 而成的字符串的起始位置
// 方便计算,记录左右一个 key 的位置
// key0key1key2key3
// ^ ^ ^ ^ ^
// start[i + 1] - start[i] 即为 Key 长度
// tmp_keys_ 将所有 key 提取为 vector
start_.push_back(keys_.size());
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char *base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
// 记录 filter 数据的偏移
// 每个 filter 数据对应一个数据分块(如果数据分块 < 2KB,可能该数据过滤器数据对应多个数据分块)
// filter0 | filter1 | xxxxx
filter_offsets_.push_back(result_.size());
// 根据 key 数据生成过滤器数据并 append 到 result_ 之后
// 默认过滤器使用 BloomFilterPolicy 见 bloom.cc 文件
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
// 处理最后一部分数据并生成磁盘格式数据
Slice FilterBlockBuilder::Finish() {
// 还有最后的数据,处理它
if (!start_.empty()) {
GenerateFilter();
}
// 记录每个 offset / 2KB = i 的索引对应的过滤器数据位置
const uint32_t array_offset = result_.size();
for (size_t i = 0; i < filter_offsets_.size(); i++) {
PutFixed32(&result_, filter_offsets_[i]);
}
// 记录过滤器数据长度
PutFixed32(&result_, array_offset);
// 记录每多少个数据分块生成一个过滤器数据
result_.push_back(kFilterBaseLg);
return Slice(result_);
}
TableBuilder
class LEVELDB_EXPORT TableBuilder {
private:
// 这部分数据被封装在 TableBuilder::Rep 中
// LevelDB 大量采用这种手法进行数据提取
Options options; // 配置
Options index_block_options; // 配置
WritableFile *file; // 文件句柄
uint64_t offset; // 偏移
Status status; // 状态
BlockBuilder data_block; // 写入 key-value 数据的 builder
BlockBuilder index_block; // 写入代表索引的 key-value 数据的 builder
std::string last_key; // 上一个 key
int64_t num_entries; // 多少个 key-value 数据
bool closed; // 完成或取消时调用
FilterBlockBuilder *filter_block; // 过滤器 builder
bool pending_index_entry; // 是否开启一个新的数据分块
BlockHandle pending_handle; // 记录数据分块的偏移信息
std::string compressed_output; // 用于压缩数据的缓存
};
// 添加一个 key-value 数据
void TableBuilder::Add(const Slice &key, const Slice &value) {
Rep *r = rep_;
// 校验一下状态
// 保证写入 key 有序
assert(!r->closed);
if (!ok())
return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
// 如果是一个新数据分块开始
if (r->pending_index_entry) {
// 校验一下,既然是一个新的数据分块,里面为空
assert(r->data_block.empty());
// 按照简介描述
// 生成上一块的索引数据 key 值
// 即上一块最有一个 key 和当前块的第一个 key 的公共前缀 +1
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
// 索引数据 value 值记录 offset 和 size
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// 过滤器 builder 缓存完整的 key 值
if (r->filter_block != nullptr) {
r->filter_block->AddKey(key);
}
// 记录一下最后的 key 值
r->last_key.assign(key.data(), key.size());
// k-value数据个数
r->num_entries++;
// 将 key-value 添加到数据分块中,由 blockBuilder 做前缀压缩
r->data_block.Add(key, value);
// 估算一个数据分块长度,如果大于设定值进行刷盘
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
// 刷盘操作
void TableBuilder::Flush() {
Rep *r = rep_;
// 强判读状态,是否有可写文件和数据
assert(!r->closed);
if (!ok())
return;
if (r->data_block.empty())
return;
assert(!r->pending_index_entry);
// 写一个 block 的数据
WriteBlock(&r->data_block, &r->pending_handle);
if (ok()) {
r->pending_index_entry = true;
// 保证文件落盘
r->status = r->file->Flush();
}
if (r->filter_block != nullptr) {
// 过滤器开启一个新数据分块
r->filter_block->StartBlock(r->offset);
}
}
// 写数据分块
void TableBuilder::WriteBlock(BlockBuilder *block, BlockHandle *handle) {
assert(ok());
Rep *r = rep_;
// 调用 blockbuilder 的 finish 准备好磁盘数据
Slice raw = block->Finish();
Slice block_contents;
CompressionType type = r->options.compression;
// 选取压缩算法,进行压缩
switch (type) {
case kNoCompression:
block_contents = raw;
break;
case kSnappyCompression: {
std::string *compressed = &r->compressed_output;
if (port::Snappy_Compress(raw.data(), raw.size(), compressed) &&
compressed->size() < raw.size() - (raw.size() / 8u)) {
block_contents = *compressed;
} else {
block_contents = raw;
type = kNoCompression;
}
break;
}
}
// 写入压缩后(如果可以压缩)数据
WriteRawBlock(block_contents, type, handle);
// 清空下缓存,重新开始新的 data_block
r->compressed_output.clear();
block->Reset();
}
void TableBuilder::WriteRawBlock(const Slice &block_contents, CompressionType type,
BlockHandle *handle) {
Rep *r = rep_;
// handle 表示当前写入文件的 offset 和 size
// 提供给索引区块设置数据时使用
handle->set_offset(r->offset);
handle->set_size(block_contents.size());
// 文件追加写入数据
r->status = r->file->Append(block_contents);
if (r->status.ok()) {
char trailer[kBlockTrailerSize];
trailer[0] = type;
uint32_t crc = crc32c::Value(block_contents.data(), block_contents.size());
crc = crc32c::Extend(crc, trailer, 1);
EncodeFixed32(trailer + 1, crc32c::Mask(crc));
// 写入压缩类型和检验数据
r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));
if (r->status.ok()) {
// 记录 offset 为偏移加大小
r->offset += block_contents.size() + kBlockTrailerSize;
}
}
}
// key-value 写入完毕,写入其他数据
Status TableBuilder::Finish() {
Rep *r = rep_;
// 刷入最后一块 data_block
Flush();
assert(!r->closed);
r->closed = true;
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// 写入非压缩的过滤器数据
if (ok() && r->filter_block != nullptr) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression, &filter_block_handle);
}
// 写入元数据
// 元数据也是 key-value 数据
// 记录 key 为过滤器名字
// 记录 value 为过滤器数据块的偏移和大小
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// 写入数据
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// 写入索引分块数据
if (ok()) {
// 生成最后一块数据区块的索引信息
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// 写入数据
WriteBlock(&r->index_block, &index_block_handle);
}
// 写入 footer 数据
// 即元数据分块的偏移和大小
// 索引数据分块的偏移和大小
// 用元数据索引过滤器数据分块
// 用索引数据索引数据分块
if (ok()) {
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}