Version版本管理和合并策略
简介
LevelDB中使用VersionSet来管理读写流程中的不同Version,每一个Version包含如图信息:
- 当前有多少
Level,每个Level都有哪些文件构成。 Version记录各Level得分用于比较合并优先级(较高得分的LEVEL先合并)。
Version与Version之间的差异由VersionEdit描述,包含增加和删除文件信息。
正常情况下VersionSet中仅有一个版本,但是由于读写并发,可能有多个读进程读时为老版本的文件,所以需要保留老版本Version,等待读流程结束后减少其引用计数值为零,从VersionSet中删除。
Version之间的先后顺序由双向链表来表示,VersionSet中的dummy节点为链表头,采用头插发最先版本为dummy->prev。
VersionSet信息持久化到MANIFEST中。
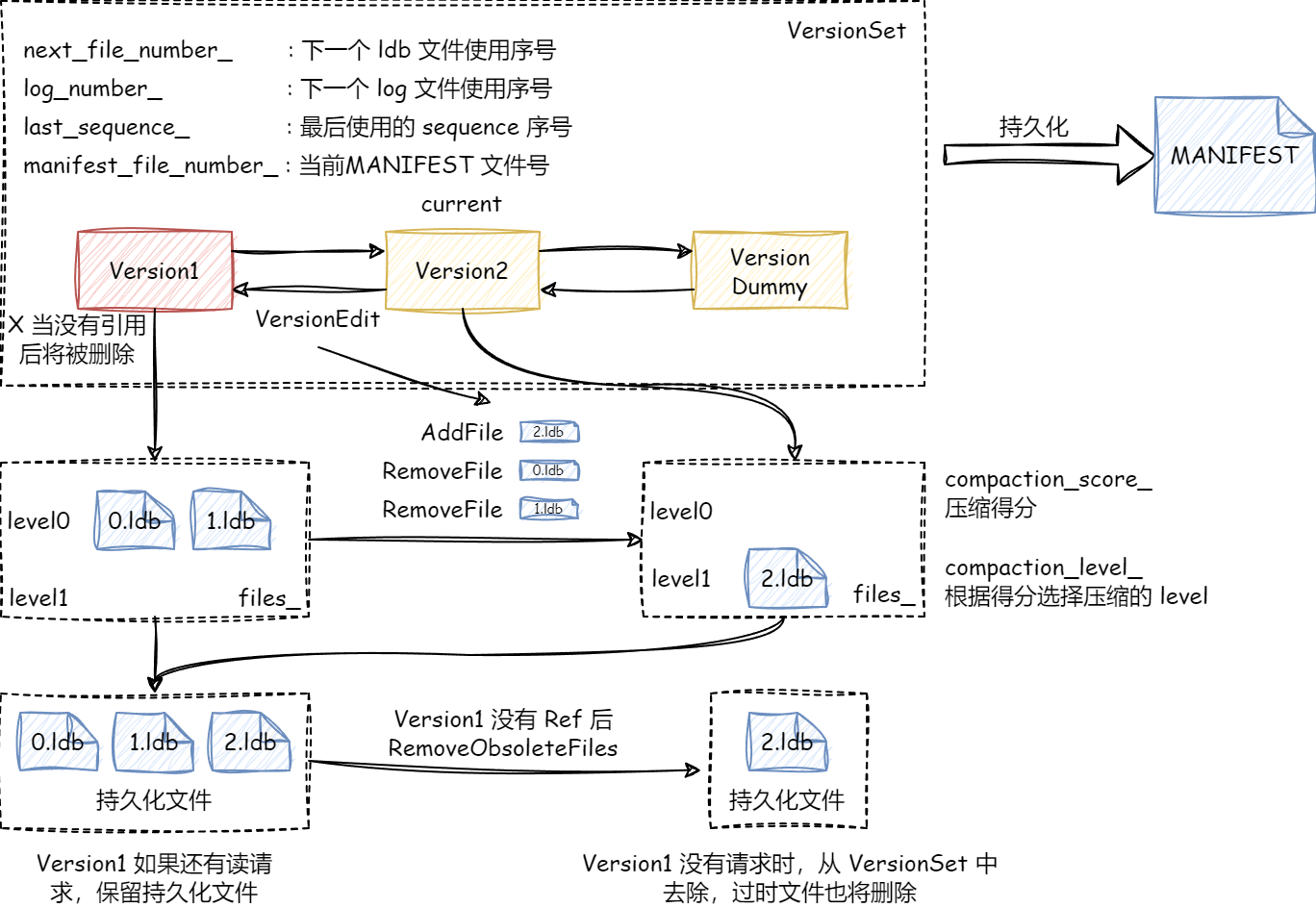
Version变化(即有持久化文件操作)的触发时机有:
MemTable超过阈值,转为imm,需要进行持久化。- 当前
LEVEL超过设定阈值,需要进行合并操作。 - 某文件读取次数超过设定阈值(读该文件的累计成本已经高于合并该文件,详细过程见得分计算分析),需要进行合并操作。
VersionSet不仅提供不同Version之间的管理,还可根据最新Version进行合并文件的选择,大致流程如下图:
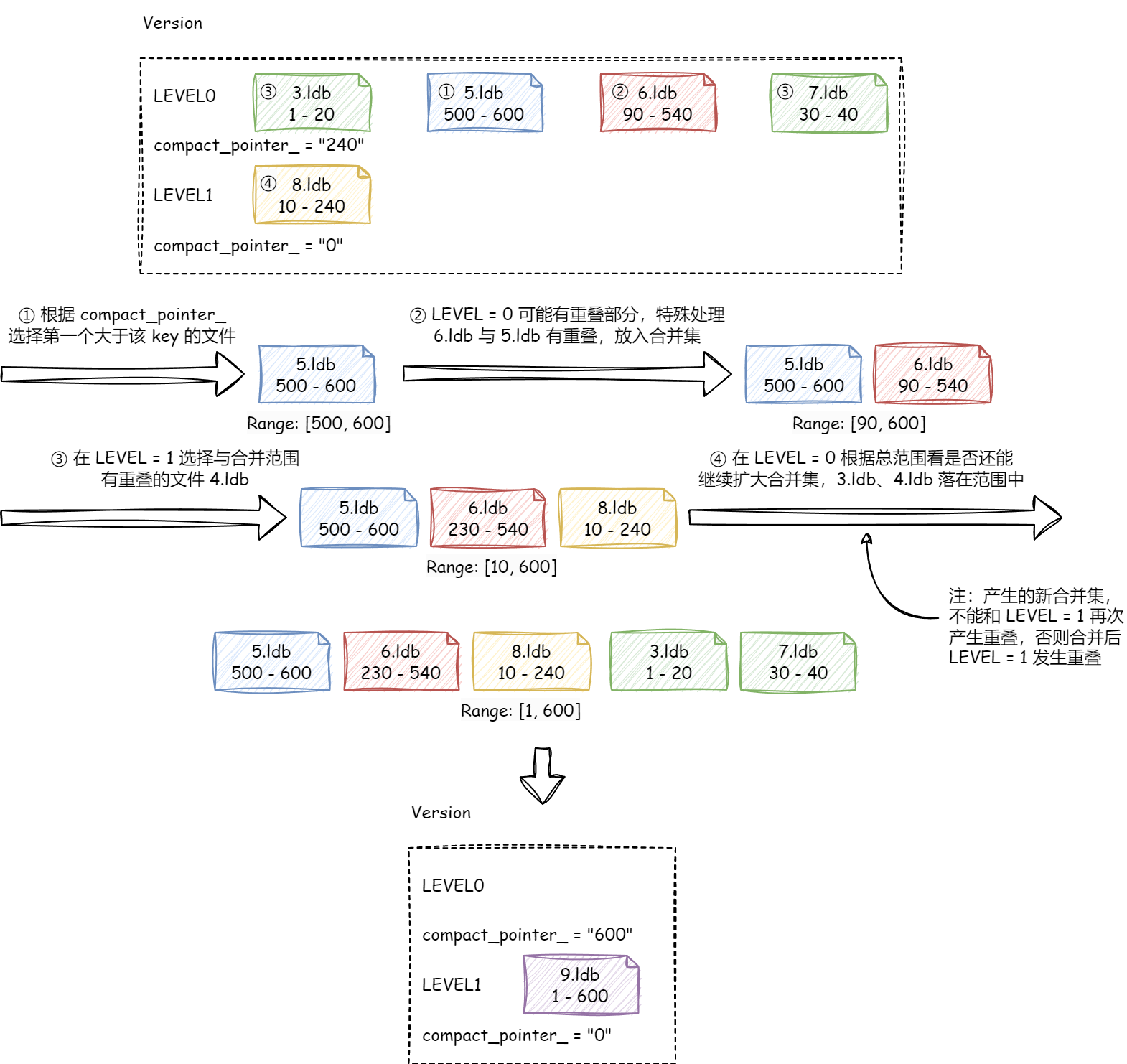
- 根据得分,其中
LEVEL0计算分数公式为SCORE = 文件数量 / LEVEL0最多允许文件数,其他LEVEL计算�公式为SCORE = 当前LEVEL文件总大小 / 当前LEVEL允许文件大小,这样能有效降低LEVEL0文件数,降低读放大(LEVEL0中读按顺序读)。 - 在需要合并的层
K中选择一个文件(LEVELDB采取“按序”选择,每次选择的文件key大于上次合并的key,没有找到从头开始)。 - 如果
K为LEVEL0,由于其允许数据有重叠,根据选取的文件,还需要在LEVEL0中将所有与之重叠的文件找出,得到合并集A。 - 除
LEVEL0外其他LEVEL不允许数据重叠,对上述选取的文件,在K+1层中查找与其重叠的文件,得到一个新的合并集A+B。 LevelDB会尽可能合并文件,对于A+B合并集范围,再尝试去K层扩大范围,得到A+B+C。注意这次扩大的集合C不能与K+1层有重叠,否则合并下去会发生重叠发生错误。当然你可以一直重复去选取能合并的段,这样的结果可能会导致所有文件都需要合并。
实现
版本变换
// edit 描述了哪些文件需要删除,哪些需要新增
// edit 来源有:
// 1. imm 表持久化后,需要新增文件
// 2. level 合并后,老文件需要删除,新文件需要新增
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
// 设置 log 文件号
if (edit->has_log_number_) {
assert(edit->log_number_ >= log_number_);
assert(edit->log_number_ < next_file_number_);
} else {
edit->SetLogNumber(log_number_);
}
// 这个变量未使用,看注释好像时兼容老版本的
if (!edit->has_prev_log_number_) {
edit->SetPrevLogNumber(prev_log_number_);
}
// 设置下一个文件号和序列号
edit->SetNextFile(next_file_number_);
edit->SetLastSequence(last_sequence_);
// 利用edit和当前使用版本产生新版本v
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
// 重新计算下得分
Finalize(v);
// 对 MANIFEST 文件的处理
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
assert(descriptor_file_ == nullptr);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
// 将 VERSION 变换信息写入 MANIFEST 文件
{
mu->Unlock();
if (s.ok()) {
std::string record;
edit->EncodeTo(&record);
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
}
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
// 写入后变换处理的版本为当前最新版本
if (s.ok()) {
AppendVersion(v);
log_number_ = edit->log_number_;
prev_log_number_ = edit->prev_log_number_;
} else {
delete v;
if (!new_manifest_file.empty()) {
delete descriptor_log_;
delete descriptor_file_;
descriptor_log_ = nullptr;
descriptor_file_ = nullptr;
env_->RemoveFile(new_manifest_file);
}
}
return s;
}
得分计算
void VersionSet::Finalize(Version* v) {
int best_level = -1;
double best_score = -1;
// 遍历每一层
// 对于0层得分 = 文件数量 / LEVEL0最大文件数
// 其他层得分 = 文件总大小 / 最大文件大小
for (int level = 0; level < config::kNumLevels - 1; level++) {
double score;
if (level == 0) {
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
} else {
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
// 对于读文件操作也需要额外变量记录得分
void Apply(const VersionEdit* edit) {
for (size_t i = 0; i < edit->compact_pointers_.size(); i++) {
const int level = edit->compact_pointers_[i].first;
vset_->compact_pointer_[level] =
edit->compact_pointers_[i].second.Encode().ToString();
}
for (const auto& deleted_file_set_kvp : edit->deleted_files_) {
const int level = deleted_file_set_kvp.first;
const uint64_t number = deleted_file_set_kvp.second;
levels_[level].deleted_files.insert(number);
}
for (size_t i = 0; i < edit->new_files_.size(); i++) {
const int level = edit->new_files_[i].first;
FileMetaData* f = new FileMetaData(edit->new_files_[i].second);
f->refs = 1;
// 当读取某文件成本过高,需要进行合并
// 例如某层有文件 A B 下一层有文件 C
// 目标 key 在 A C 中
// 读取查询花费10ms,IO速率为100MB/s
// 合并 AC 需要花费 250ms
// 查询25次A不如合并AC时间,合并后只需要查询一次
// 具体查询次数预估公式见代码 <- 调优经验值
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
levels_[level].deleted_files.erase(f->number);
levels_[level].added_files->insert(f);
}
}
合并策略
Compaction* VersionSet::PickCompaction() {
Compaction* c;
int level;
// 判断需要合并的原因
// 1. 查询某文件次数超过阈值
// 2. 当前层大小超过阈值
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != nullptr);
if (size_compaction) {
level = current_->compaction_level_;
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
// 选择一个文件去合并,描述见简介
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
if (c->inputs_[0].empty()) {
c->inputs_[0].push_back(current_->files_[level][0]);
}
} else if (seek_compaction) {
// 如果是一个文件读太多,只用合并该文件
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
} else {
return nullptr;
}
c->input_version_ = current_;
c->input_version_->Ref();
// LEVEL0是可以重叠的,需要将重叠部分都选上
// c->inputs_[0]就是当前level选择的合并段
// c->inputs_[1]就是level+1选择的合并段
if (level == 0) {
InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
}
// 扩大选择的段
SetupOtherInputs(c);
return c;
}
// 扩大选择的段,这里请对照简介的图文描述
void VersionSet::SetupOtherInputs(Compaction* c) {
const int level = c->level();
InternalKey smallest, largest;
// AddBoundaryInputs 这个函数是用于解决一个bug的见
// https://github.com/google/leveldb/issues/320
// 简单来说就是如果一个段a范围为[l1,r1],b为[l2,r2]
// 如果r1==l2那么这两个段要一起选上,否则合并后会出现问题
// 例如删除key1放在b,但是b被合并到下一层去了
// 由于前面的level是新数据,最后读取到的是a值未删除的
// 出现数据不一致问题
// 这个感觉直接放在GetOverlappingInputs比较为<= ?
// 没搞明白为什么这样改的
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
GetRange(c->inputs_[0], &smallest, &largest);
// 从下一层获取重叠部分
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
// 重新计算下范围,用来扩大
InternalKey all_start, all_limit;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
if (!c->inputs_[1].empty()) {
std::vector<FileMetaData*> expanded0;
// 根据新加入level+1的范围看看,level还能不能加入新的文件
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]);
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]);
const int64_t expanded0_size = TotalFileSize(expanded0);
if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size <
ExpandedCompactionByteSizeLimit(options_)) {
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit,
&expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
// 看看新加入的文件会不会又和level+1重叠了
// 重叠了,要么套娃加入level+1的文件,要么放弃扩大level层文件
// 这里选择后者
if (expanded1.size() == c->inputs_[1].size()) {
Log(options_->info_log,
"Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n",
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
}
// 取合并后文件与level+2层有多少重叠
// 用于计算是否仅挪动该文件即可
// 例如当前level只有一个文件需要合并,level+1层没有,那么可以进行两种操作
// 1. 直接挪动文件到level+1层
// 2. 压缩和挪动到level+1层
// 取决于level+2层如果想和level+1层合并的成本,如果成本过大还是将先压缩,这样
// 挪动到level+1时再去和level+2层合并时能够减少merge成本
if (level + 2 < config::kNumLevels) {
current_->GetOverlappingInputs(level + 2, &all_start, &all_limit,
&c->grandparents_);
}
// 更新下数据
compact_pointer_[level] = largest.Encode().ToString();
c->edit_.SetCompactPointer(level, largest);
}